
As our business needs grow in complexity, so do our apps. Consider how much business logic is or should be synchronous in our modern apps. The list is endless.
Network requests, database access, animations, anything that takes more than a few milliseconds are all long-running operations that modern app architecture should take into account.
You need to be extra careful if you want to build this on Android. By default, there is only one main render thread. All the logic in activities, fragments, but also view models and services run on the same thread. Not only that, but that same thread is also tasked with a lot of behind-the-scenes work to make sure your app runs smoothly and looks nice.
It's a good idea to remove as much work as possible from this thread. But how?
T(h)read Lightly
There are big challenges that come with asynchronous ways of computation. You need to take into account edge cases, race conditions, deadlocks, etc. Not only that, but Android has the added problem of complex lifetimes.
Does your view model survive long enough for database/network request to finish? Does your fragment survive long enough for animation decode to finish? Resources could be leaked if they're not explicitly handled.
The problems associated with threading are not trivial. There's a reason why frameworks such as ReactiveX (Rx) exist.
Existing Implementations
Rx's JVM implementation RxJava is one of the ways to address these issues via reactive programming. Reactive programming was very popular a few years and arguably transformed how we write applications today. This being said, people are already writing critical postmortems and Rx debatably didn't gain as much traction because of its steep learning curve and complicated APIs.
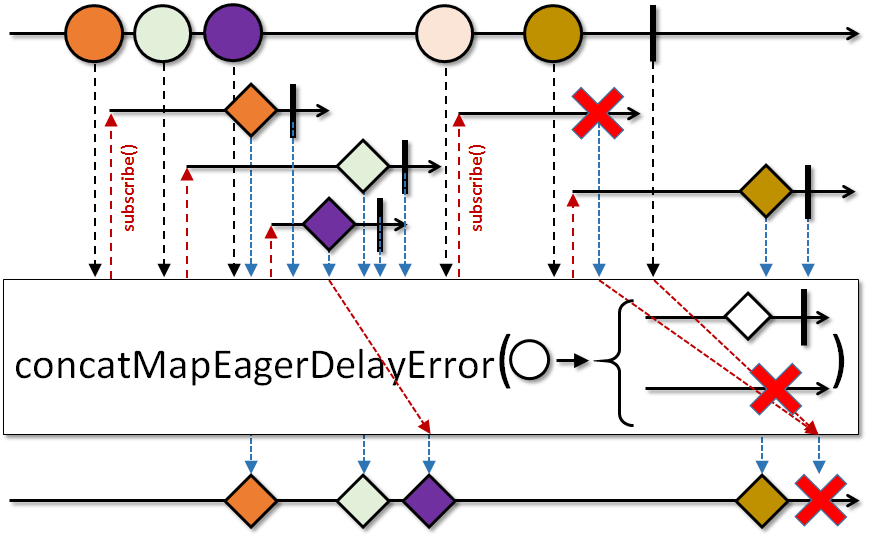
While there are other frameworks, Android's limited Java 8 APIs don't really give us a lot of choice besides LiveData (with limited functionality beyond the UI).
Enter Kotlin Coroutines
Kotlin made good inroads with language-level support for asynchronous operations via Coroutines. Without going too deep into coroutines in this blog post, suffice to say that they address a big chunk of Rx's functionality with easy composition, management of asynchronous operations, and bonus functionalities like structured concurrency.
The part we're still missing, then, are tools to manage streams of data, analogous to Rx's Observable and Flowable. But first, some basics on streams.
Streams
A stream is a representation of data emissions over time. Many things in our apps fit the stream model: a stream of user clicks, a stream of location updates our application listens to, a stream of network updates we subscribe to, etc.
An important property of a stream is whether it is hot or cold. This is explained in more depth in this great overview. Kotlin has different components based on the use case:
Channels

Channels are conventionally hot. They are used mainly for messaging and synchronizing between coroutines (and behind the scenes of Flow). To summarize the important bits:
- emissions to receivers are 1-1 (non-simultaneous) for a regular Send/ReceiveChannel, and multicast (delivered to all receivers) for BroadcastChannel[1]
- sending/receiving can be a suspending operation to ensure synchronization, (there are also non-suspending async variants which add to buffer/fetch current value from the buffer if available)
- ConflatedChannel's (and its ConflatedBroadcastChannel[1] variant) receivers always get the most recent emission

- being not scoped to a coroutine scope and need to be manually closed/cancelled makes them useful for cross-scope communication (another solution:
StateFlow/SharedFlow[1])
[1]SharedFlow is in development to replace all kinds of BroadcastChannels.
Flow

Flow is conventionally cold[1]. It brings a clean API for collecting values and operators, and it allows for easy management of resources. Because it runs within a coroutine scope, flows are only consumed when the observer calls a suspending terminal operator like collect and aren't active after it (the Flow itself can await its coroutine cancellation or completion and "clean after itself").
Besides the benefits of running within a coroutine scope, Flow has a lot of operators defined on it (RxJava users will recognize most) which all accept suspending lambdas. As such, Flow doesn't care whether your transformations on it are synchronous or not.
Another benefit is context preservation. By default, the terminal operator (collecting) will run inside the context it's being collected in, even if the actual computation takes place in a different thread pool.
[1]actual implementations (i.e. StateFlow/SharedFlow) might not enforce this.
StateFlow
StateFlow is a recent addition and is roughly equivalent to LiveData[1] - multicast emissions to subscribers and the ability to update from wherever you have a reference to its mutable implementation (MutableStateFlow). It keeps its most recent value (conflation) that any new subscription gets as the first emission.
It is analogous to Rx's BehaviorSubject and was arguably the final functionality that brought the whole Coroutines library to almost the same level with Rx[2].
[1] There are some minor differences specific to LiveData, like waiting a set amount of time before detaching subscriptions to handle short configuration changes (rotation).
[2]Rx is a library with many operators and utilities, but in my opinion the current state of kotlinx.coroutines handles the vast majority of practical use-cases and is easier to use and adapt to your needs.
In Practice
To demonstrate the usefulness of flows, I've built a small app displaying a list of movies from OMDB based on the search query. It has a toggle to filter out the movies after 2010 and a snackbar notifying the user when the connection is unavailable.
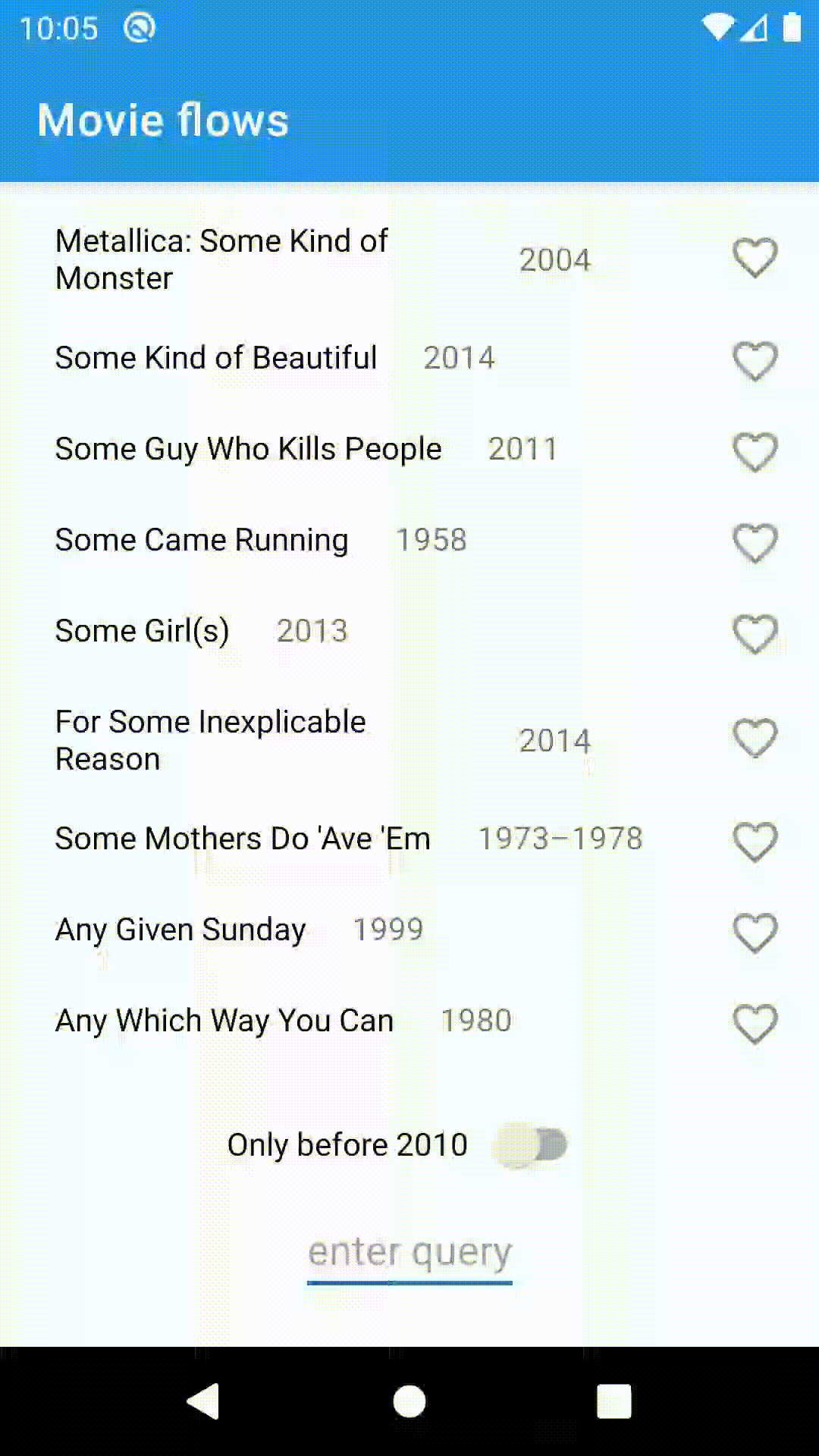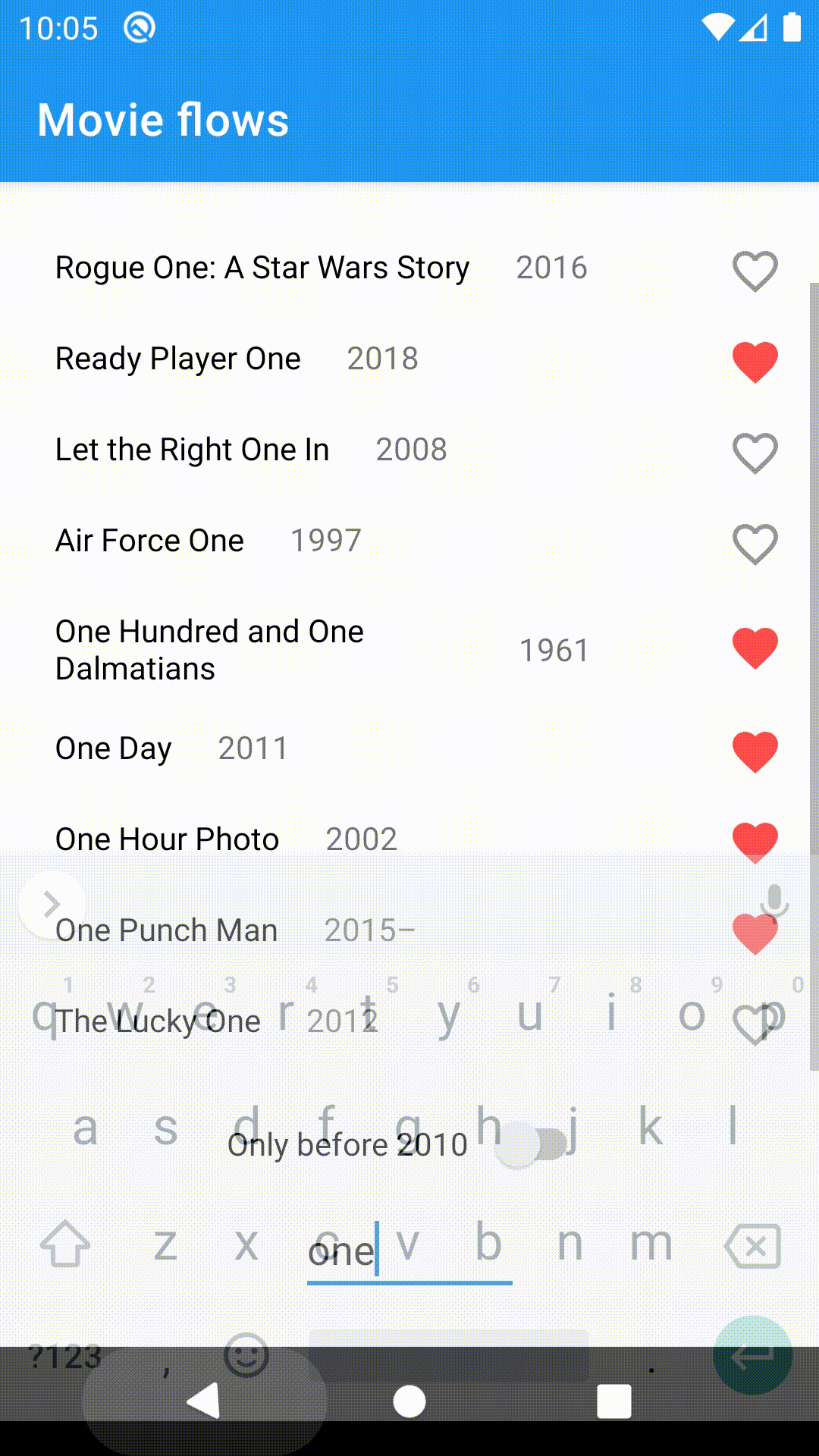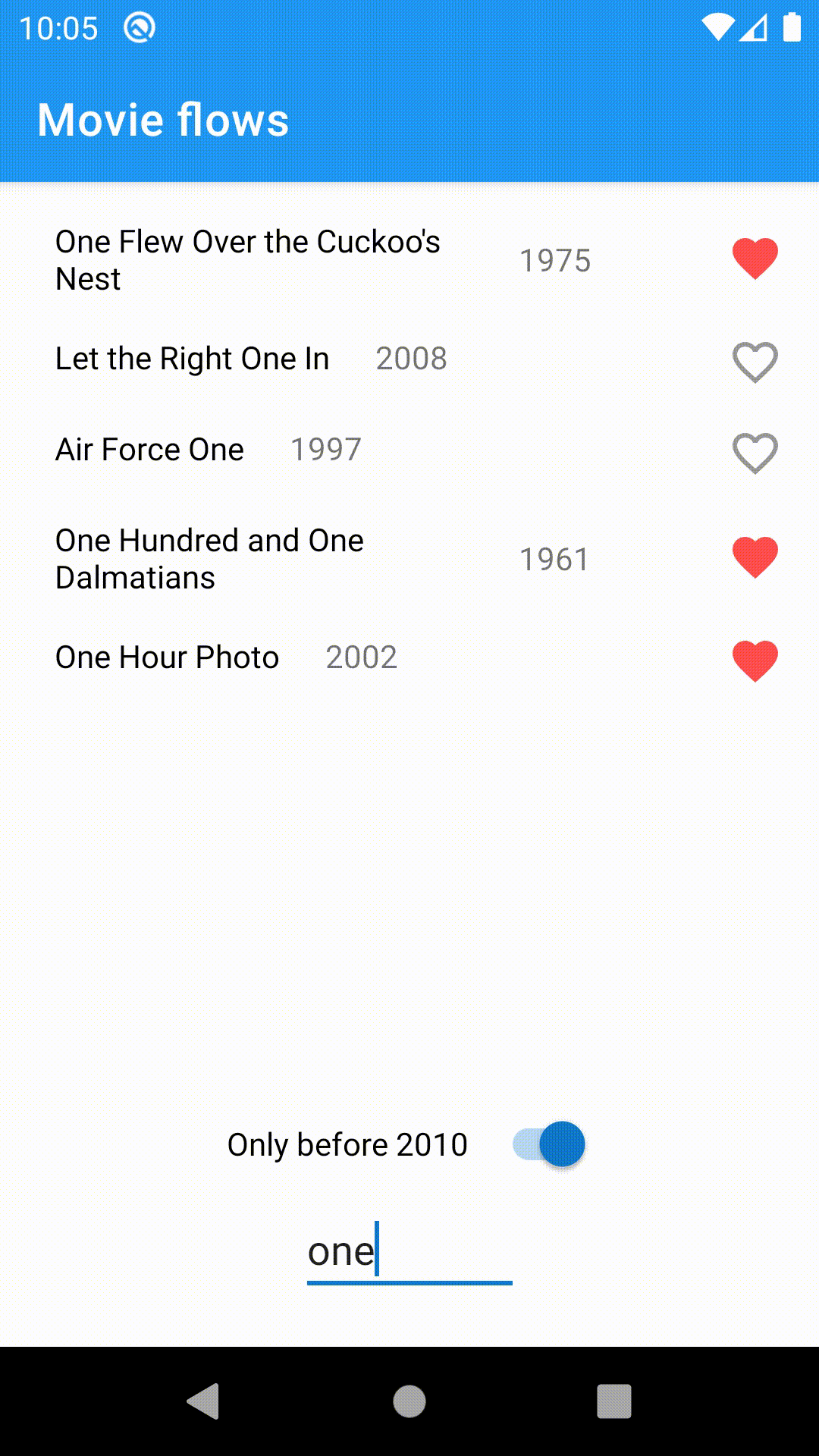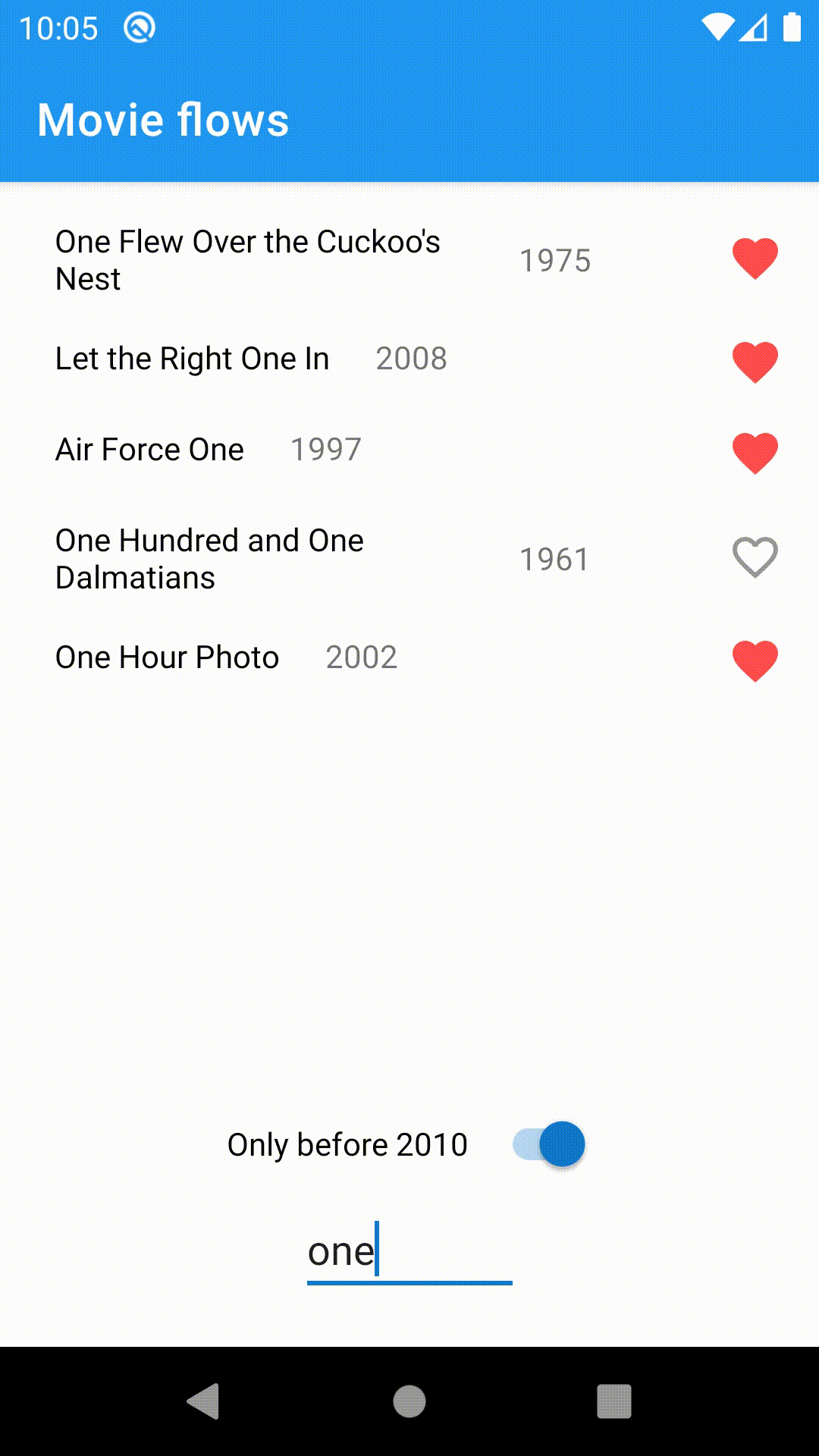
Let's take a look at the implementation details. The idea is to minimize the amount of state in our components and instead work with flows directly, making use of its powerful operators.
Fragment (UI event flows)
The fragment is tasked with the following:
- displaying the list of movies
- displaying the network unavailable snackbar
- routing the UI event flows to the view model
First on our list are UI events. Clicks, input changes, toggle changes, etc. By default, these are exposed via regular callbacks.
Using the callbackFlow builder, we can transform any callback-based API into a flow. And because coroutines run within a context, we can use another feature called awaitClose, which exposes a callback firing when the flow's send channel is closed.
This means that if we collect a flow inside a provided lifecycleScope, awaitClose can be used to clear up any resources we used in the process. No more hooking up onto onResume/onPause/etc ... and keeping a separate reference to that resource!
fun Context.networkAvailableFlow(): Flow<Boolean>
= callbackFlow {
val callback = object : ConnectivityManager.NetworkCallback() {
override fun onAvailable(network: Network) {
offer(true)
}
override fun onLost(network: Network) {
offer(false)
}
}
val manager = getSystemService(Context.CONNECTIVITY_SERVICE)
as ConnectivityManager
manager.registerNetworkCallback(NetworkRequest.Builder().run {
addCapability(NetworkCapabilities.NET_CAPABILITY_INTERNET)
build()
}, callback)
awaitClose { // Suspends until channel closed
manager.unregisterNetworkCallback(callback)
}
}
Above is an example of a flow of network events exposed as a convenient extension function. As long as it runs within the correctly-scoped coroutine context (i.e. lifecycleScope), it takes care of its own resources.
Similarly, we can have a flow of input events:
fun EditText.afterTextChangedFlow(): Flow<Editable?>
= callbackFlow {
val watcher = object : TextWatcher {
override fun afterTextChanged(s: Editable?) {
offer(s)
}
override fun beforeTextChanged(s: CharSequence?, start: Int, count: Int, after: Int) {}
override fun onTextChanged(s: CharSequence?, start: Int, before: Int, count: Int) {}
}
addTextChangedListener(watcher)
awaitClose { removeTextChangedListener(watcher) }
}
Why should you have these exposed as flows? Because it makes your UI code less cluttered with references and cleanup. You can then also use the operators to do more complex transformations on them, as they pass onto the presentation layer and beyond.
In this use case I only used a debounce operator, since we don't want to make a request and update on every button press. Instead, we want to wait 400 milliseconds to settle:
lifecycleScope.launchWhenResumed {
binding.input.afterTextChangedFlow().debounce(400)
.collect {
viewModel.updateQuery(it.toString())
}
}
It's easy to work with flows with the bundled lifecycleScope. In these 6 lines we also get the debounce functionality and automatic resource cleanup.
View model
The presenter layer routes the UI events into the repository:
- it sets up the repository
- fetches the initial UI state
- routes the UI input events to the repository within its coroutine scope
- exposes the repository's list of events
It also exposes its flow as a LiveData,which is a convenient extension on any flow:
private val repo = MoviesRepository(...)
val queried = repo.filteredEntities.asLiveData()
fun updateQuery(query: String) = viewModelScope.launch {
repo.fetch(query = query)
}
fun updateToggle(enabled: Boolean) = viewModelScope.launch {
repo.updateOnlyOld(enabled)
}
fun setFavourite(movieEntity: MovieEntity) = viewModelScope.launch {
repo.setFavourite(entity = movieEntity)
}
...
Repository
The repository transforms different forms of data to create the final flow of UI results:
- it combines the flows of DataStore and Room to create the final displayed movies flow
- persists the query and toggle state
- updates the favorite flags
First, we create the flows of persisted states of our input query and toggle:
private val queries = store.data.map { it[KEY_QUERY] ?: "" }
.distinctUntilChanged()
private val onlyOldEnabled = store.data.map { it[KEY_ONLY_OLD] ?: false }
.distinctUntilChanged()
The DataStore API exposes its storage as a flow, so all we need to do is map to the key we're interested in and skip consecutive repetitions via distinctUntilChanged.
With this we can compose our final flow. As dao.getAllMoviesByQuery(query) already returns Flow<List<MovieEntity>> (implementation by Room), we can directly compose it with the UI state flows.
First, we call flatMapLatest on a flow of queries to make sure we subscribe to a new database flow whenever the query changes. This also makes sure the previous flow is disposed of, so we don't leak any resources:
queries.flatMapLatest { query ->
dao.getAllMoviesByQuery(query).distinctUntilChanged()
Next, we combine the queried movies with the flow of toggle booleans to filter out the new movies. This simple but powerful operator allows creating any kind of operations that are commonly used.
val filteredEntities = queries.flatMapLatest { query ->
dao.getAllMoviesByQuery(query).distinctUntilChanged()
.combine(onlyOldEnabled) { movies, onlyOld ->
if (onlyOld) {
movies.filterNot { it.isNew() }
} else {
movies
}
}
}
The usefulness of Room's Flow return type is demonstrated whenever we make a query change:
store.edit { it[KEY_QUERY] = query }
val models = try {
api.searchMovies(query).Search ?: return
} catch (e: Exception) {
e.printStackTrace()
return
}
models.map { MovieEntity.from(it, query) }
.takeIf { it.isNotEmpty() }?.let {
dao.insertMovies(it)
}
First, we persist a new query to the DataStore. This triggers the flatMapLatest to switch to a new database flow which (almost immediately) returns whatever currently persists in the database.
Next, we attempt to fetch the API response. If it fails, we return. There might still be enough persisted storage so that the UI was still updated. If not, we insert the results into the database. This again triggers the dao.getAllMoviesByQuery(query) we are currently subscribed to, which updates the UI with the updated (network) data.
And that's mostly it! The adapter is a ListAdapter with a diff utility for animating the data changes and the rest is mostly provided to us by JetPack libraries.
[1]the sample uses experimental Coroutine APIs and DataStore (in alpha). For simplicity, it does not use dependency injection (i.e. Hilt). Flow is expected to be fully stable with the upcoming 1.4 coroutines release.
To Wrap Up
This was just a short preview of what is possible with the new Kotlin Flow APIs. Hopefully it convinced you to give it a try, especially if you liked Rx and felt a need for a modern refresher.
A good place to start is to use the built-in flows (Room, DataStore, Paging 3, Store, etc.) and go from there, or by experimenting with creating your own whenever you think a streaming representation makes more sense. Google also has a Codelab on it and made a good introduction to it on its IO.
Good luck and happy coding!
SHARE:



