X-Teamers don't rest on their laurels. When they're not working, they're learning. When they're not learning, they're exploring. When they're not exploring, they're creating open-source projects.
At least, that's what X-Teamer Ariel Díaz does. His RestQL.js library resolves nested-linked API calls (find it here on GitHub and npm). I asked Ariel how the library came into being and how it helps other developers.
Imagine you’re talking to someone who has little technical knowledge. How would you explain your project?
Think of a box that has both data and references to other boxes. For example, let's say you were to build a robot. The separate pieces of the robot are stored in multiple boxes in a garage, each box tagged with a number on top.
You start by opening box #1, which contains the chest of the robot, along with a card that says where the head is stored. Next, you open box #2, which contains the head of the robot and two cards saying where the arms are stored. You open boxes #3 and #4, with each one containing a robot arm and a card saying where the hands are located.
You carry on this way, opening boxes until you find the last piece of robot in a box without a card. That's the basic principle of RestQL.js.
I see! And why did you create the library?
I was part of a group of friends who were all learning JavaScript and React.js. We'd set this goal to create a simple app that would showcase our weekly progress.
My project was a single-page web app that was meant to be a virtual Pokédex that people could use to search for information about a Pokémon. Inevitably, the first thing I researched was how and where I'd get my data. I found the PokéAPI, which I thought would solve all my data-related problems. Turns out that wasn't true...
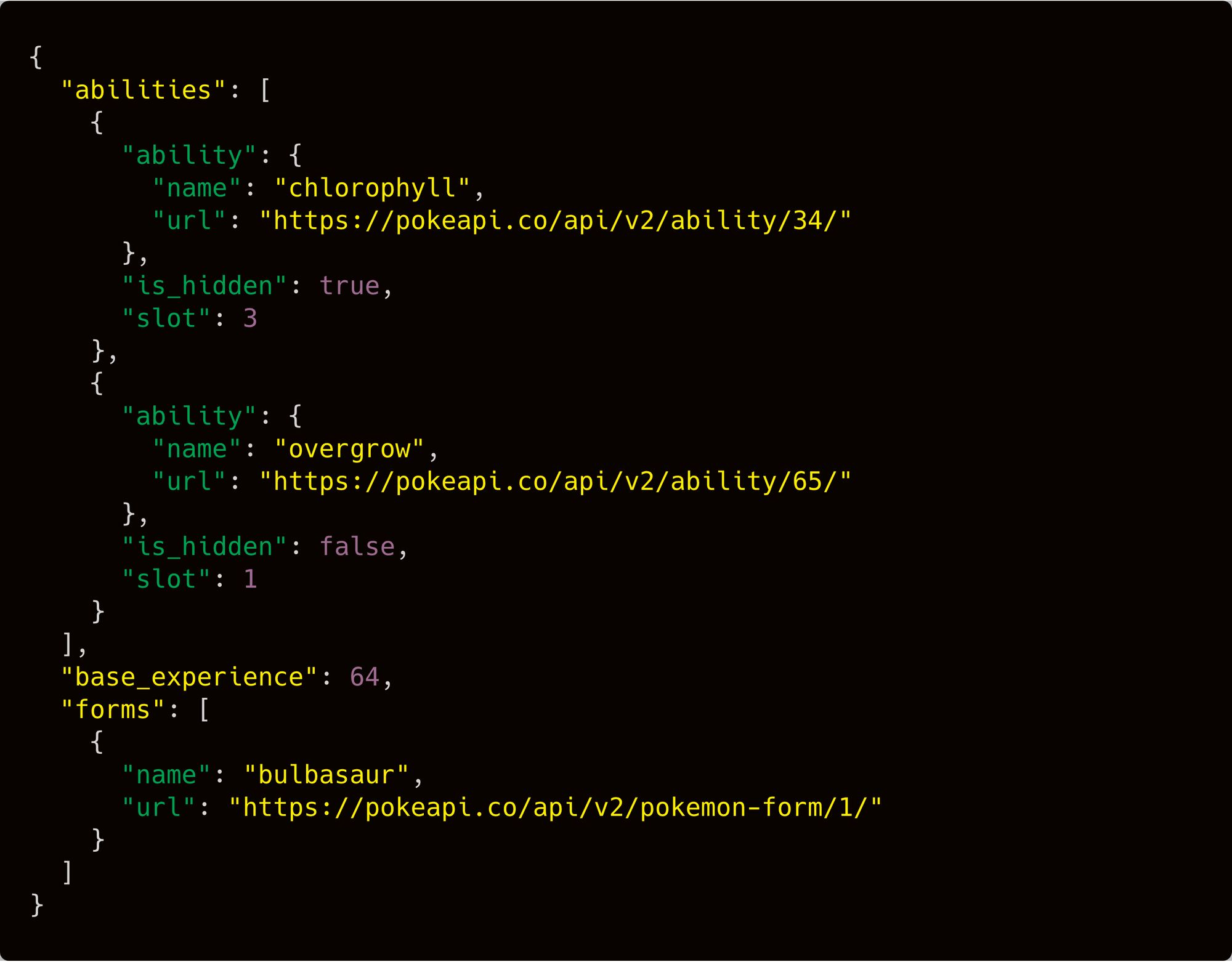
The PokéAPI itself only gives you the basic information of a Pokémon. It contains a lot of references to other endpoints that separate the primary data from the Pokémon. That was a problem, because I didn't just need the basic information of a Pokémon. I wanted specific details about their abilities, stats, and special moves.
I didn't think writing code to go over the different properties in response was such a great solution, so I decided to create a library. That's how RestQL started.
So it came into being for a very practical reason. Now, without any analogies, what exactly does RestQL do?
RestQL allows you to dynamically resolve the nested-linked resources of a RESTful API by specifying a set of properties to describe the paths.
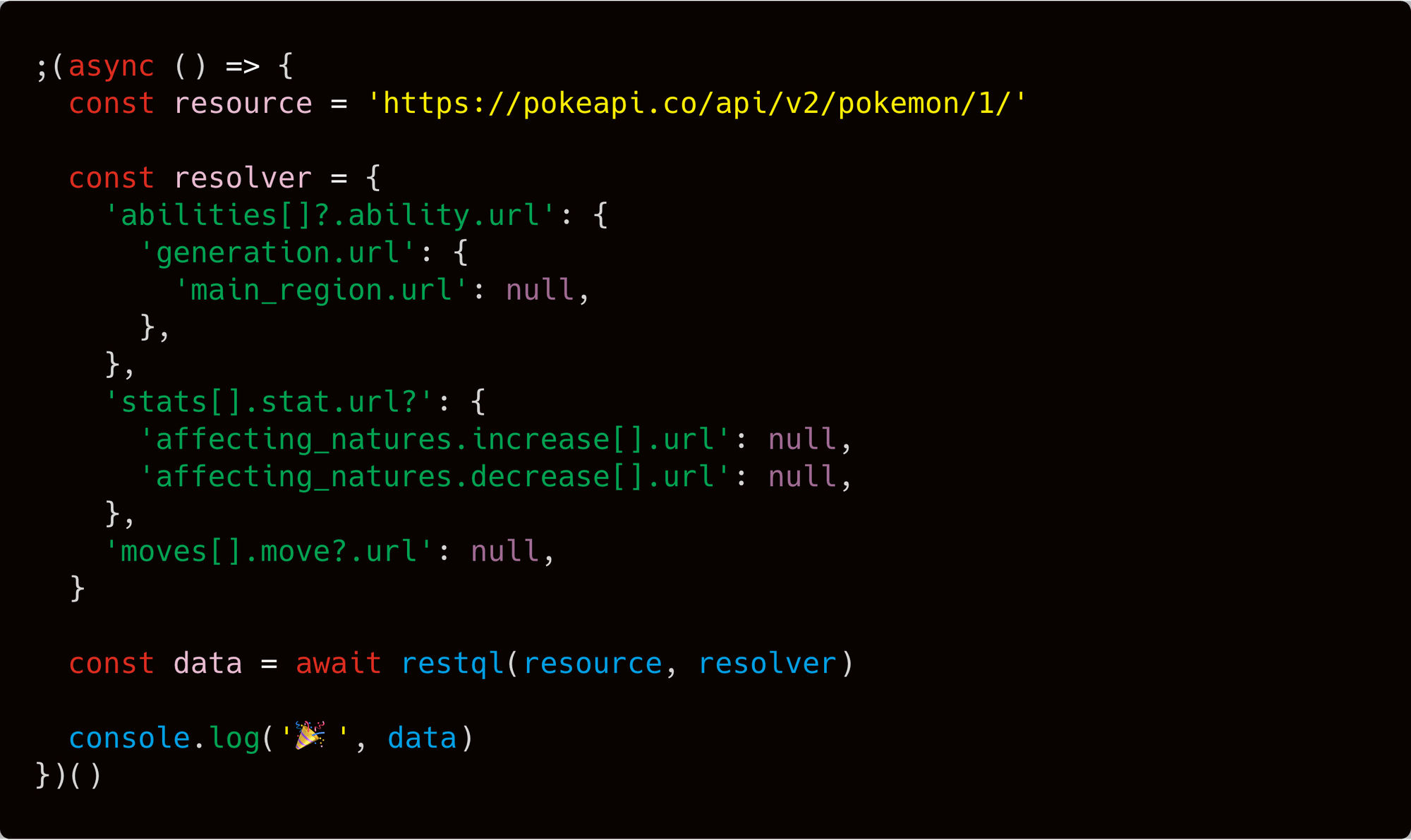
At every level, each property describes a path to the nested resource within the current resource. RestQL resolves the sames and calls the subsequent resolver against them until the base case (null) is reached. From that point, it returns back the merged responses.
That sounds useful. How much time did it take to create initially and how much time does it take to maintain it?
It took me approximately three months at first. The initial commit was made on Nov 12 of 2017 and the first major release was published on Jan 12 the following year. In terms of maintainability, I spent one month making minor adjustments to it, until the 12th of Feb 2018.
At this point, the library is pretty mature, as it's achieved 4 out of the 5 milestones defined in its roadmap. The last milestone I plan to complete in the following few months. Given the narrow scope of the library, no issues have been opened so far, which has allowed me to focus on the next set of features without any distractions.
What’s the fifth milestone you want to achieve?
It’s called Support for recursive resolvers, which can be useful for cases when a parent node shape represents a child one. For example, a Pokémon can evolve, but at the same time, be an evolution by itself.
The idea is to implement a new quantifier, in the form of wildcards ($0, $1, $2, …, $N), so a child node can refer to any parent node path within the resolver and is able to reduce the size and maintainability of the same, by not having to update a resolver in multiple places in the code.
Do you promote your library in a particular way or do you just leave it on Github & npm for people to find?
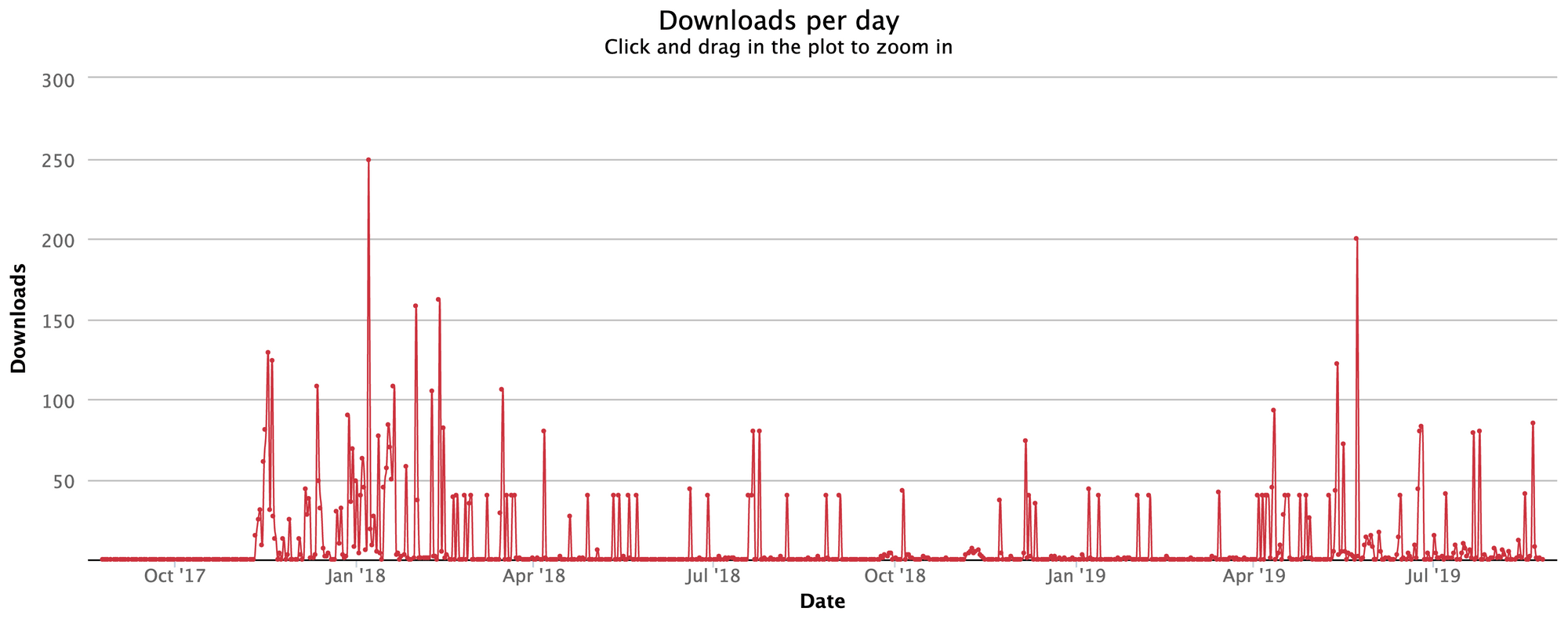
I’d say I don’t promote it, but I did spread the word among friends when I first released it. Right now, the library sits at an average of 137 weekly downloads from npm, something that's been consistent over the last two years.
I also created a post on Medium, explaining in detail how the library works with an example of how it helps you avoid manual loops over responses. Otherwise, given that I don’t have all that much traction in tech on social media, I don't promote it.
What was the most difficult aspect of the project? Your biggest learning?
That would be promises, and having to manage asynchronous requests to then merge them into a single object as part of the final response.
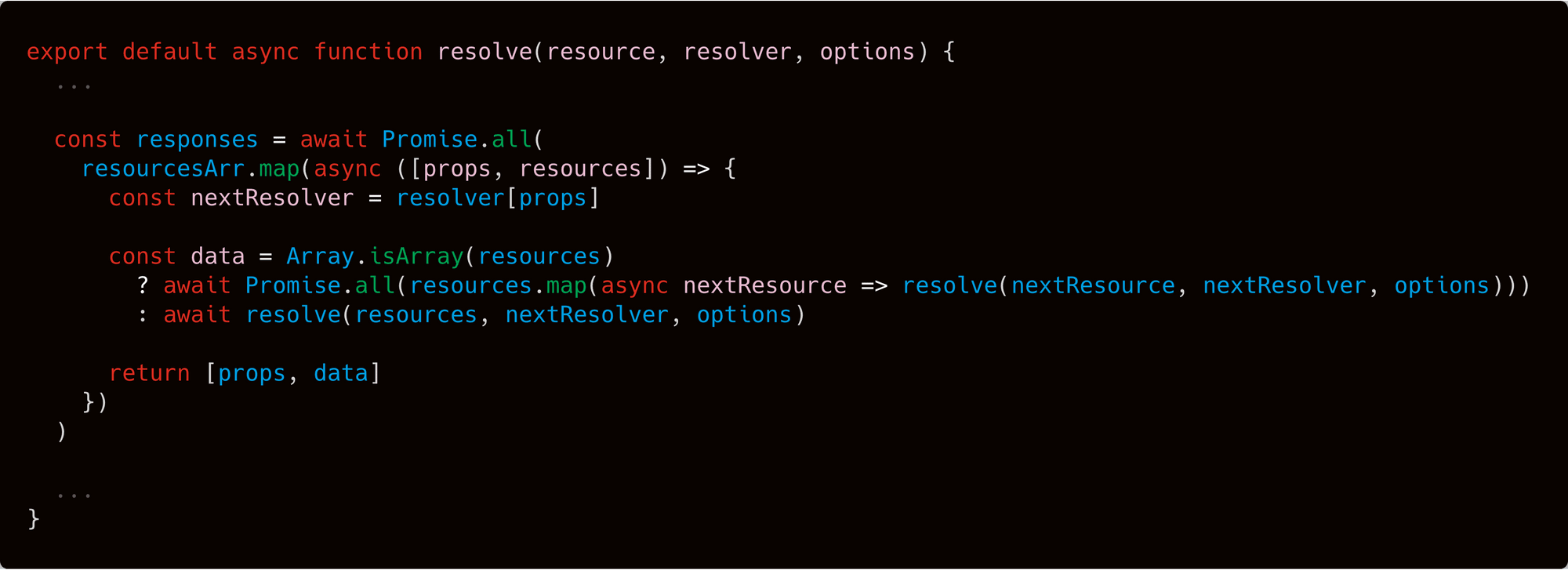
The above code snippet shows the core of RestQL, which is to parse the properties defined in the resolver and spread them across subsequent calls. All this is done by leveraging the power of recursion while processing multiple requests in parallel (because of the nature of asynchronous code).
Thank you so much for explaining your project! Best of luck with the fifth milestone.
SHARE: