Imagine that you have a monolithic app hosted on AWS and you're considering splitting it up into microservices. Is it worth the effort? Why should you switch from a monolithic architecture to microservices and how can you do so efficiently?
That's what this article will answer. It will explain how you can create a monolithic app on AWS, what problems you might face, and how you can switch over to microservices to solve those problems.
Creating Our Monolithic App
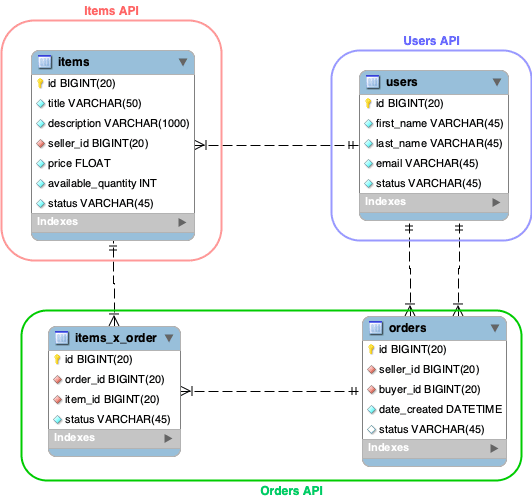
Let's assume we're working on the backend of a new e-commerce app. We've already designed a basic database that looks as follows:

As you can see, the first entity – called items – stores every item that we're selling in our e-commerce app. Each item has a reference to the seller, who's a registered user. A buyer can be a user too. Every time someone buys a set of items from a seller, an order is created.
Let's take a look at all the endpoints that we need to make this design work:
# Handle users:
POST /users
PUT /users/$userId
GET /users/$userId
GET /users/search?country_id=AR&limit=50&offset=0
# Handle items:
POST /items
PUT /items/$itemId
DELETE /items/$itemId
GET /items/search?seller_id=1&status=active&limit=50&offset=0
# Handle orders:
POST /internal/orders
PUT /internal/orders/$orderId
GET /orders/$orderId
GET /orders/search?seller_id=1&buyer_id=2&status=handling
Disregarding payments, shipping, and status updates, we need around twelve different endpoints to handle all the entities in our DB. So let's get to work.
Implementing the Logic
We're using Java as our programming language for this project and we're placing all the logic in our github.com/coolcompany/marketplace-api repo. Since we're going to use AWS to host and serve our API, we need to create the following infrastructure:

The end user interacts directly with an Elastic Load Balancer that has two EC2 instances inside. Each of these instances interacts with the RDS database in which we've built the tables of the design mentioned above.
Lots of Traffic
Let's now assume our app is deployed in production and everything works like a charm. We average around 3,000 requests per minute (RPM) without any errors whatsoever. Awesome.
But, after three months running this configuration and some heavy-duty marketing, an increasing number of people start using our app. The business does great and we're growing like crazy, to the point where our RPMs skyrocket from 3,000 to a little bit over 10 million!
But we stay calm. Thanks to AWS, we can keep adding instances to our infrastructure to deal with this traffic without facing any hiccups. At least, so we think.
A Deeper Traffic Analysis
Let's take a look at all our endpoints and see how they're behaving in production.
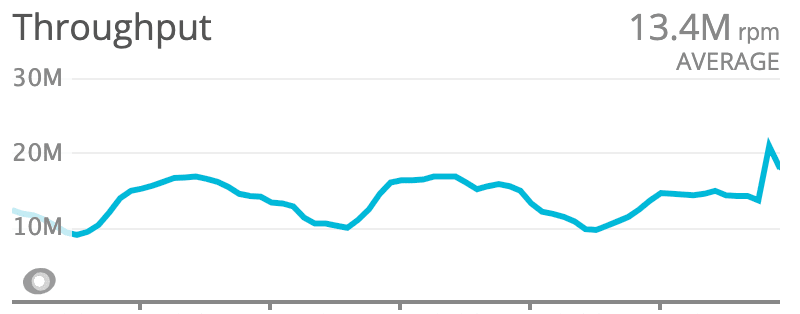
Items - GET & Search
This endpoint consumes nearly 96% of our total requests. Based on the traffic patterns and request origins, we notice that the endpoint is being consumed from our frontend and native applications.
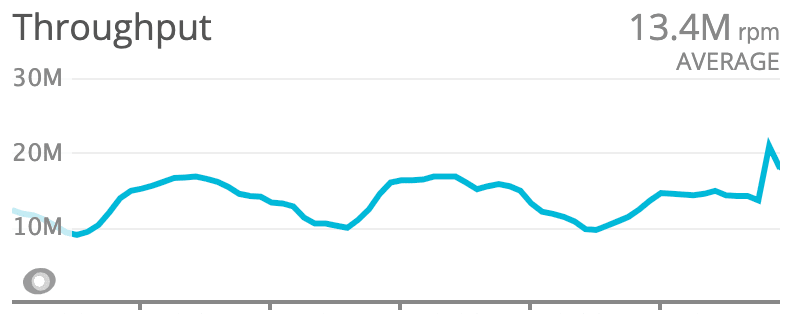
Items - POST & PUT
This endpoint has about 20 RPMs (which means that we're creating around 20 products per minute). There are some days with traffic spikes above 100 RPMs, but they're not organic.
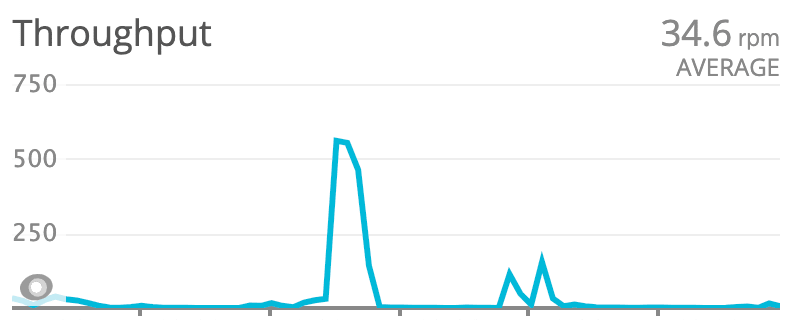
Looking at this endpoint, we notice that we haven't been creating any new items for about a month. This seems to have happened after a new version of the app was deployed. This is not good.
Orders - POST & PUT
This is where we create and update orders. Every new POST request comes from a user trying to buy something in our marketplace. Looking at these endpoints, we notice that we're getting close to 10 RPMs during the day and pretty much no RPMs at night.
Conclusions From Our Traffic Analysis
- When (not if) the database goes down, the entire app and all of its endpoints will go down. This is less than desirable, to say the least.
- For about a month, no new items have been created. We've only found out about this now, because we didn't have any metric or alarm for this in our system.
- The 10M RPMs of the GET & search
itemsendpoints were working okay. This meant that the general uptime for allitemsendpoints was 99.9998%, which is why we received no alert for our failing POST & PUTitemsendpoints. - In this sense, if all endpoints stopped working except for the GET
itemsendpoint, we'd never get an alert from AWS. - Every time we need to make a change to an endpoint, we need to deploy the whole app again. We have no control over the section of the app we're making changes to.
Moving to Microservices
The microservices architecture can fix pretty much all these issues. Let's start by taking every business capability of our app and creating a different API for each one of them.
Each business capability now has its own API and its own database. So when the items API goes down, users and orders will keep on working and responding as expected.
But what about traffic? If we have different APIs, how are we going to decide where to send the incoming request? We need some sort of routing system. That's where Nginx comes in.
How Does Our Infrastructure Look?
To accommodate the above, we'll need to make quite a few changes to our infrastructure. Since we're using AWS, we can rely on its services to help us.
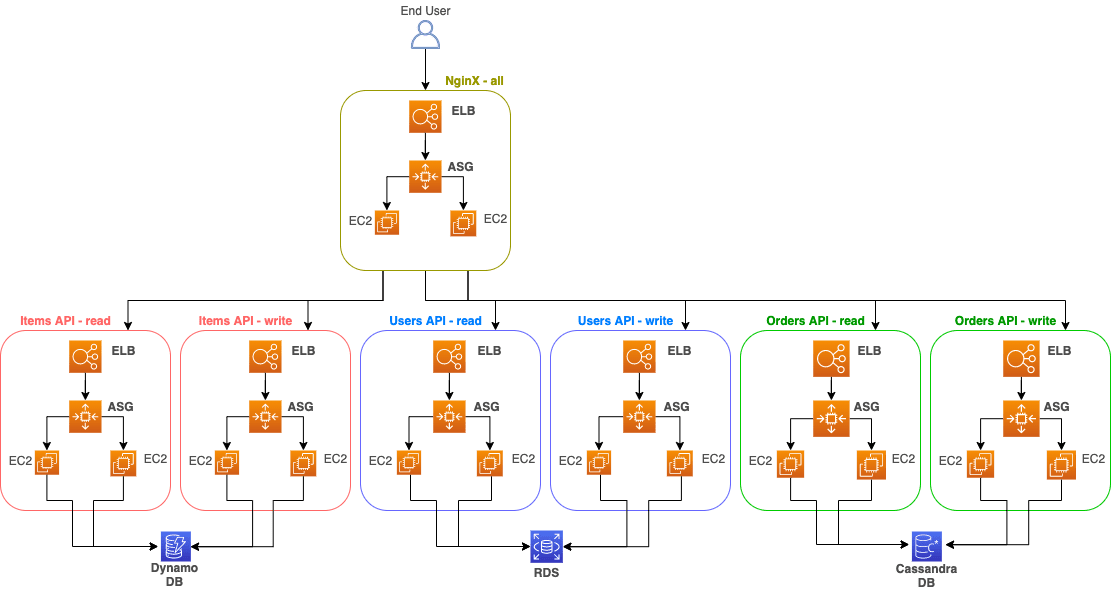
Using Nginx as a Traffic Router
We can use Nginx as the entry point of our app by relying on its highly performant proxy features. The Nginx layer will handle every incoming request and redirect it to the corresponding app based on the rules we create. These rules take into account both the request URI and the HTTP method.
Here's an example of such a set of rules:
# Rules for Users API:
location ~ ^/users.* {
if ($request_method ~ ^(POST|PUT|DELETE)$) {
proxy_pass lb-users-api-write.your_zone.elb.amazonaws.com;
}
proxy_pass lb-users-api-read.your_zone.elb.amazonaws.com;
}
# Rules for Items API:
location ~ ^/items.* {
if ($request_method ~ ^(POST|PUT|DELETE)$) {
proxy_pass lb-items-api-write.your_zone.elb.amazonaws.com;
}
proxy_pass lb-items-api-read.your_zone.elb.amazonaws.com;
}
# Rules for Orders API:
location ~ ^/orders.* {
if ($request_method ~ ^(POST|PUT|DELETE)$) {
proxy_pass lb-orders-api-write.your_zone.elb.amazonaws.com;
}
proxy_pass lb-orders-api-read.your_zone.elb.amazonaws.com;
}
As you can see, based on the requested URI and HTTP method, we can proxy_pass a request to the corresponding Elastic Load Balancer in our VPC.
This is also one of the reasons why it's important to set descriptive names when creating ELBs in AWS.
All the Benefits
Let's take a quick look at all the benefits that this move to microservices has given us:
- The final user reaches our Nginx layer. From there, we can use the requested URI and HTTP method to redirect the request to whichever ELB is appropriate.
- We have a separate app for each use case, organized by business capability. Each app can grow in the amount of code, complexity, and impact without affecting any of the other apps.
- Each app has an ELB in the front. Underneath that, we have an Auto Scaling Group (ASG) that allows us to scale these microservices based on the traffic any of them receives.
- We've separated our apps into two different ELBs: one for POST, PUT, and DELETE requests and another for GET, HEAD, and OPTIONS. We use the Nginx layer to redirect appropriately, based on the request information.
- Each app has its own repo in GitHub and can be modified without affecting the other apps. Each new version can be tagged in GitHub too.
- Each app can now have its own database. This could be any type of database we want. As long as we don't change the public interface and signature of the endpoints, we could change databases without anyone noticing.
More specifically, here's how microservices solves the problems we had with our previous design:
- If a database is down, only that microservice will fail. All the others will still work correctly.
- We can have metrics per ELB and generate alerts based on error rates, response times, or any other metric. More importantly, we can rely on the AWS metric system to respond automatically without human intervention.
- We can use Nginx to separate read from write requests. This means that the 20 RPMs in our write ELB are now 100% of the requests we're receiving there. If all of them fail, we'll have a 100% failure rate in this ELB, while the read ELB will remain the same.
- Our separate apps can communicate via REST API calls, which means that we are free to use whichever programming language and design pattern we want for the requirements of each specific app.
I hope this example has shown you the tangible benefits of moving from a monolithic app to microservices in AWS.
SHARE: